
Retrieval-Augmented Generation (RAG) represents a monumental shift in artificial intelligence (AI), bridging the gap between static large language models (LLMs) and the dynamic need for real-time knowledge updates. Unlike traditional LLMs, which rely solely on pre-trained static data, RAG introduces a method to dynamically fetch and integrate relevant, up-to-date information. But what exactly makes RAG so impactful, and why is it garnering such attention in the AI community?
What is RAG?
Meta AI researchers pioneered Retrieval-Augmented Generation (RAG) to tackle knowledge-intensive tasks. By combining an advanced information retrieval system with a text generation model, RAG unlocks new levels of adaptability and accuracy. Unlike traditional LLMs, RAG allows for efficient fine-tuning and updating of its internal knowledge without the need to retrain the entire model from scratch.
Here’s how it works:
RAG takes an input query and retrieves a set of highly relevant supporting documents from a source database (e.g., Wikipedia). These documents are concatenated with the input prompt and passed to the text generator, which produces a final output. This dynamic retrieval mechanism ensures that RAG adapts to evolving facts and remains reliable even when the underlying information changes over time. Traditional LLMs, by contrast, are limited by their static, parametric knowledge.
Performance Benchmarks:
- RAG excels in various benchmark tests, including Natural Questions, WebQuestions, and CuratedTrec.
- On MS-MARCO and Jeopardy questions, RAG’s outputs are notably more factual, specific, and diverse.
- It also improves verification tasks, as seen in FEVER fact-checking datasets.
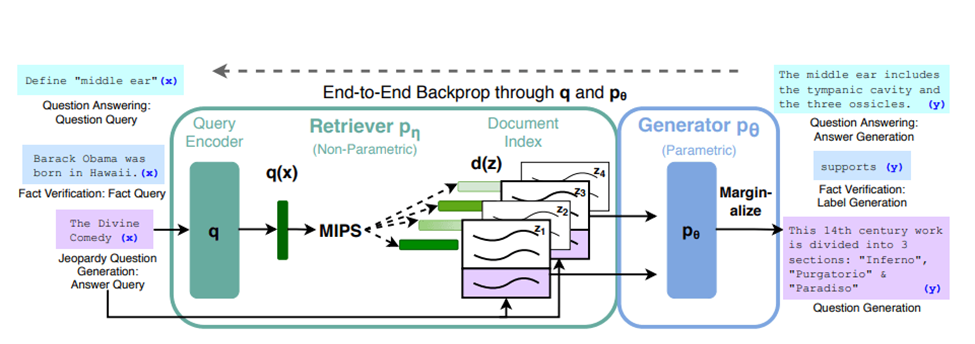
Figure 1: Overview of our approach. We combine a pre-trained retriever (Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query x, we use Maximum Inner Product Search (MIPS) to find the top-K documents zi . For final prediction y, we treat z as a latent variable and marginalize over seq2seq predictions given different documents.
Image source: Lewis Et Al. (2021, April 12). Retrieval-Augmented Generation for Knowledge-Intensive NLP tasks. arxiv.org. Retrieved December 19, 2024, from https://arxiv.org/pdf/2005.11401
How Does RAG Work?
The RAG framework operates through three main components:
1. Indexing: External data—such as text files, database records, or long-form documents—is split into manageable chunks. These chunks are then converted into vector representations (embeddings) using a deep learning model. These embeddings, designed to capture semantic meaning, are stored in an optimized vector database capable of performing efficient nearest-neighbor searches.
2. Retrieval: When a query or prompt is input into the system, it is similarly converted into an embedding. The system searches the indexed database to identify the most relevant document chunks based on semantic similarity. The top-k results (e.g., the top 5 most relevant chunks) are then retrieved.
3. Generation: The original query, combined with the retrieved document chunks, is fed into a text generation model (e.g., GPT-3). This model generates a coherent and relevant response, leveraging the retrieved information to ground its output in factual data.
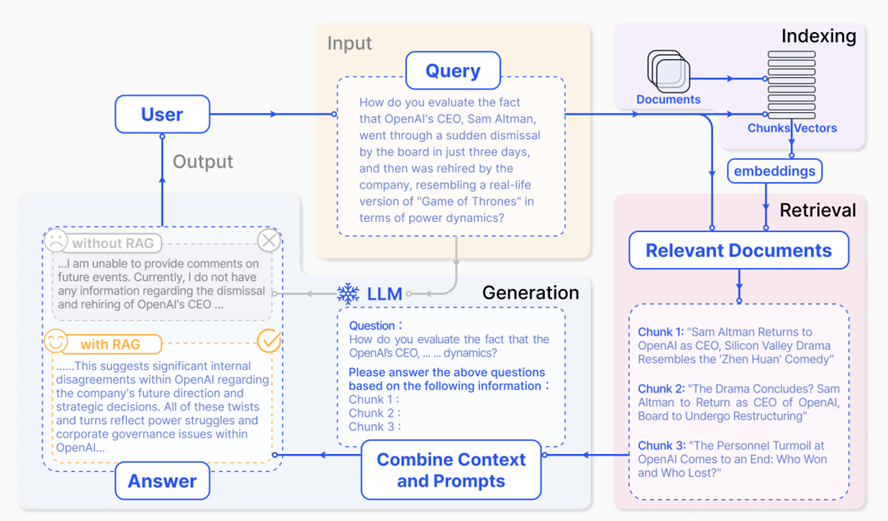
Fig. 2. Image Source: Yunfan Gao Et Al. (2024, March 27). Retrieval-Augmented Generation for Large Language Models: A Survey. arxiv.org. Retrieved December 19, 2024, from
https://arxiv.org/html/2312.10997v5
A representative instance of the RAG process applied to question answering, it mainly consists of 3 steps.
1) Indexing. Documents are split into chunks, encoded into vectors, and stored in a vector database.
2) Retrieval. Retrieve the Top k chunks most relevant to the question based on semantic similarity.
3) Generation. Input the original question and the retrieved chunks together into LLM to generate the final answer.
Why Use RAG?
RAG offers significant advantages over traditional LLMs:
1. Accuracy: By generating responses based on the retrieved documents, RAG ensures outputs are based on factual and verifiable sources which reduces hallucinations (fabrication of false information) commonly observed in standalone large language models (LLMs).
2. Adaptability: Fetches domain-specific or updated information, making it suitable for specialized fields like healthcare or finance. RAG can easily integrate with custom knowledge bases tailored to specific industries or tasks, such as healthcare, legal services, or finance. This adaptability allows it to deliver precise, context-aware answers without requiring extensive retraining of the underlying model.
3. Explainability: A hallmark feature of RAG is its ability to include references to the sources it uses for generating responses. This transparency not only boosts user confidence but also aids in verifying the authenticity of the generated information.
4. Multi-Step Reasoning Capabilities: RAG excels at tasks requiring multi-hop reasoning, where multiple pieces of evidence must be connected to answer a query. By retrieving and synthesizing relevant information across diverse documents, RAG enables more complex and nuanced decision-making compared to traditional systems.
RAG Paradigms
RAG has evolved through three key paradigms:
1. Naive RAG: Early versions of RAG focused on basic retrieval and generation. While effective, these implementations struggled with imprecise retrieval and integrating retrieved data seamlessly.
2. Advanced RAG: Optimizations such as improved indexing, query rewriting, and context compression were introduced to address the shortcomings of Naive RAG. These enhancements improved both the relevance and usability of retrieved data.
3. Modular RAG: Offers flexibility by allowing dynamic adjustments to retrieval, generation, and augmentation processes. This paradigm supports iterative improvements and task-specific customizations.
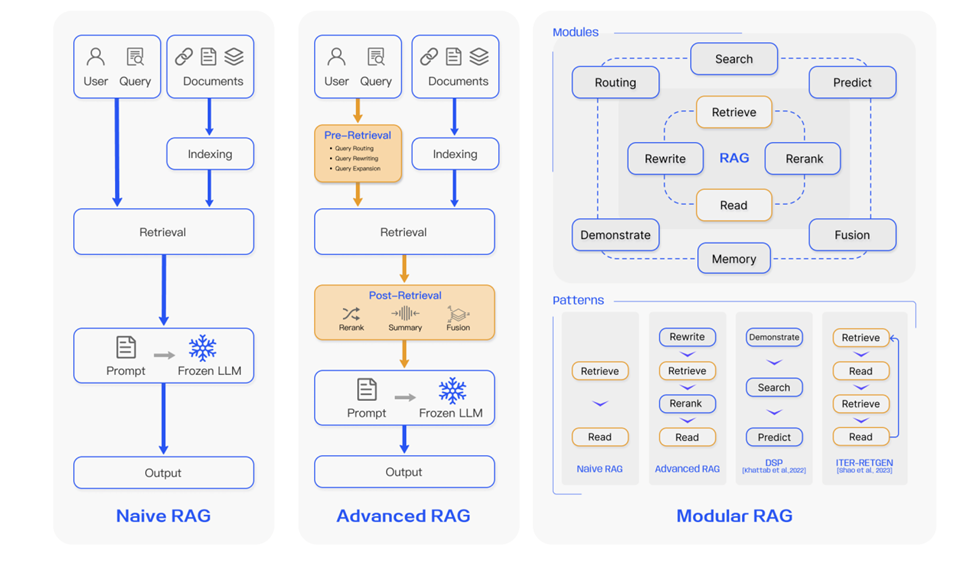
Fig. 3. Image Source: Yunfan Gao Et Al. (2024, March 27). Retrieval-Augmented Generation for Large Language Models: A Survey. arxiv.org. Retrieved December 19, 2024, from https://arxiv.org/html/2312.10997v5
Comparison between the three paradigms of RAG, (Left) Naive RAG mainly consists of three parts: indexing, retrieval and generation. (Middle) Advanced RAG proposes multiple optimization strategies around pre-retrieval and post-retrieval, with a process similar to the Naive RAG, still following a chain-like structure. (Right) Modular RAG inherits and develops from the previous paradigm, showcasing greater flexibility overall. This is evident in the introduction of multiple specific functional modules and the replacement of existing modules. The overall process is not limited to sequential retrieval and generation; it includes methods such as iterative and adaptive retrieval.
Applications of RAG
RAG is transforming various industries with its ability to handle knowledge-intensive tasks:
- Customer Support: AI chatbots powered by RAG can retrieve accurate responses from manuals, documents, or FAQs, enhancing user experience and reducing resolution times.
- Healthcare: By sourcing data from medical journals and clinical studies, RAG provides evidence-based answers to healthcare professionals and patients alike.
- Legal Assistance: Answering queries with references to legal documents and precedents to offer precise and reliable legal advice.
- Education: Enhancing learning experiences by sourcing information from textbooks, educational resources and research papers.
Challenges in RAG
Despite its benefits, RAG faces challenges:
- Noise in Retrieval: It might sometimes pull irrelevant, redundant, or even conflicting data which degrades the quality of the response, as the generator might incorporate incorrect or unnecessary information. Improving the precision of the retriever remains a critical challenge.
- Integration Complexity: Seamlessly combining retrieved data with generated content remains difficult. Combining retrieved data with the query during the generation phase is complex, especially when the retrieved content varies significantly in format or context. Ensuring that the model effectively synthesizes the retrieved information without disrupting the coherence of the output is an ongoing challenge.
- Latency: Real-time retrieval can slow down response generation. Real-time retrieval from external knowledge bases introduces latency, which can slow down response times, especially when working with large datasets. Additionally, the computational overhead of encoding, retrieving, and generating can make RAG systems resource-intensive, limiting scalability in production environments.
- Hallucinations Despite Retrieval: While RAG reduces hallucinations compared to standalone LLMs, it doesn’t eliminate them entirely. If the retrieved documents are incomplete or ambiguous, the generator might still fabricate details, reducing the reliability of the system. Better grounding mechanisms are needed to mitigate this.
- Evaluation of RAG Outputs: Evaluating the quality of RAG-generated outputs is challenging because it involves assessing both the accuracy of the retrieval and the coherence of the generation. Current evaluation metrics often fall short in capturing the nuances of multi-hop reasoning and explainability.
Future of RAG
The future of RAG is exciting, with several research directions:
1. Improved Retrieval Techniques: Incorporating graph-based or multi-modal retrieval for diverse data types like images or videos.
2. Adaptive Systems: Allowing RAG models to decide dynamically when retrieval is necessary.
3. Integration with Fine-Tuning: Combining RAG with techniques like reinforcement learning to improve alignment between retrieved content and generated responses.
Why RAG Matters
As the reliance on AI grows, the need for systems that are accurate, explainable, and adaptable becomes paramount. RAG not only enhances the capabilities of LLMs but also makes them more trustworthy and useful in real-world applications. Whether it’s answering customer queries or solving complex research questions, RAG is paving the way for the next generation of intelligent systems.