
Polars is a modern DataFrame library, purpose-built for data manipulation and analysis. It is especially effective for large datasets that challenge traditional tools like Pandas. Polars, written in Rust, employs advanced techniques like lazy evaluation, parallel processing, and efficient memory management to deliver exceptional performance.
Despite its lower adoption compared to Pandas—~2.6 million downloads as of December 2023 versus Pandas' ~140 million downloads—Polars is rapidly becoming a preferred choice among data professionals. Its ability to address Pandas' inefficiencies while introducing a modern, flexible API makes it a strong contender for advanced data processing workflows.
Integration Options
Polars supports seamless integration into existing data workflows, making it easier for teams to transition or adopt its features incrementally:
1. Native Support:
Some modern libraries natively support Polars, eliminating the need for conversions.
2. Automatic Conversion:
Polars DataFrames can be converted into Pandas DataFrames, and vice versa. However, automatic conversion can be inefficient for large datasets due to memory overheads.
- From Pandas to Polars: Use pl.from_pandas().
For example:
import polars as pl df_polars = pl.from_pandas(df_pandas) # df conversion From Pandas to Polars
- From Polars to Pandas: Use pl.to_pandas().
For example:
import polars as pl df_pandas = df_polars.to_pandas() # df conversion From Polars to Pandas
3. Manual Conversion:
Use Apache Arrow for zero-copy conversions to minimize memory impact. This is the most efficient conversion for larger datasets.
For example:
import polars as pl import pyarrow as pa # Convert pandas_df to Arrow Table arrow_table = pa.Table.from_pandas(df_pandas) # Convert Arrow Table to Polars DataFrame df_polars = pl.from_arrow(arrow_table) # Convert Polars DataFrame back to Arrow Table arrow_table_back = df_polars.to_arrow() # Convert Arrow Table back to Pandas DataFrame df_pandas_back = arrow_table_back.to_pandas()
Advantages of Polars
1. Performance Enhancements:
- Rust Backend: Polars is built in Rust, allowing low-level optimizations for speed and memory.
- Multi-threading: Utilizes all available CPU cores, unlike Pandas, which is single-threaded.
- Columnar Storage: Stores data in a columnar format for faster analytical processing.
2. Lazy Evaluation:
In Polars, computations are deferred until explicitly requested. This allows Polars to:
- Identify redundant operations and optimize execution.
- Process only the required data, improving speed and efficiency.
Example:
lazy_df = df.lazy() # No computation yet
result = lazy_df.filter(pl.col('price') > 100).select(['name', 'price']).collect()
3. Efficient Memory Management:
- Polars uses zero-copy reads where possible, minimizing memory usage.
- With Arrow-based columnar storage, Polars handles mixed data types and large datasets more efficiently.
4. Simplified API:
- Polars provides an intuitive syntax for chaining operations, simplifying complex transformations.
5. Type Safety and Query Optimization:
- Polars enforces stricter type safety than Pandas, reducing runtime errors.
- Query optimization ensures that only the minimal required operations are executed.
Benchmarking: Pandas vs. Polars
Let’s dive into how Pandas and Polars perform across critical data processing tasks such as reading, filtering, writing, and memory usage. This detailed benchmarking exercise uses a 1.4 GB CSV file containing 12.4 million rows. The results highlight both libraries' performance metrics and operational differences.
1. Setting Up the Environment
To begin, we set up the environment with the required libraries (Pandas, Polars, os, and psutil) and utility functions to measure execution time and memory usage
import pandas as pd
import polars as pl
import time
import os
def measure_time(func, *args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
return result, end_time - start_time
# File path
filename = "file_path/filename.csv"
# Get the size of the CSV file in bytes
file_size = os.path.getsize(filename)
#Get the row count by reading the file line by line
with open(filename, "r") as file:
row_count = sum(1 for line in file) - 1 # Subtract 1 for the header
# Convert size to MB
file_size_mb = file_size / (1024*1024)
print(f"Size of Csv File: {file_size_mb:.2f} MB")
print(f"Row in File: {row_count}")
2. Benchmarking with Pandas
Benchmark the performance of the Pandas library by measuring the time taken to read a CSV file, filter its contents, and write the results back to a new CSV file. We will also assess the memory usage of the DataFrame after these operations.
By systematically measuring these metrics, we can gain insights into how Pandas handles data manipulation tasks, particularly with larger datasets. This benchmarking will serve as a reference point for comparing Pandas’ performance against Polars in subsequent sections.
#-------------------Pandas Benchmarking------------------------
df_read, pd_read_time = measure_time(pd.read_csv, filename)
pd_filter_time = measure_time(lambda: df_read.query("WireTransactionType == 'Other'")) [1]
pd_write_time = measure_time(df_read.to_csv, "output_pandas.csv", index=False) [1]
pandas_memory_usage = df_read.memory_usage(deep=True).sum() / (1024*1024) # Size in MB
print("Pandas Read Time:", pd_read_time, "seconds")
print("Pandas Filter Time:", pd_filter_time, "seconds")
print("Pandas Write Time:", pd_write_time, "seconds")
print("Pandas Memory Usage:", pandas_memory_usage, "MB")
3. Benchmarking with Polars
Next, we perform the same operations using Polars. Unlike Pandas, Polars:
- Uses multi-threading for parallelism.
- Implements lazy evaluation, deferring execution until necessary.
- Handles memory more efficiently using the Apache Arrow columnar format.
#-----------------------Polars Benchmarking-----------------------
df_read_pl, pl_read_time = measure_time(pl.read_csv, filename)
pl_filter_time = measure_time(lambda: df_read_pl.filter(pl.col("WireTransactionType") == "Other")) [1]
pl_write_time = measure_time(df_read_pl.write_csv, "output_polars.csv") [1]
polars_memory_usage = df_read_pl.estimated_size() / (1024*1024) # Size in MB
print("\nPolars Read Time:", pl_read_time, "seconds")
print("Polars Filter Time:", pl_filter_time, "seconds")
print("Polars Write Time:", pl write_time, "seconds")
print("Polars Memory Usage:", polars_memory_usage, "MB")
Running this snippet will provide us with critical insights into how Polars performs in terms of speed and memory efficiency, allowing for a direct comparison with Pandas.
4. Displaying the Results
Now that we have completed the benchmarking for both Pandas and Polars, it's time to analyze and compare the results with a test_file.csv. We will present the metrics for read time, filter time, write time, and memory usage for each library.
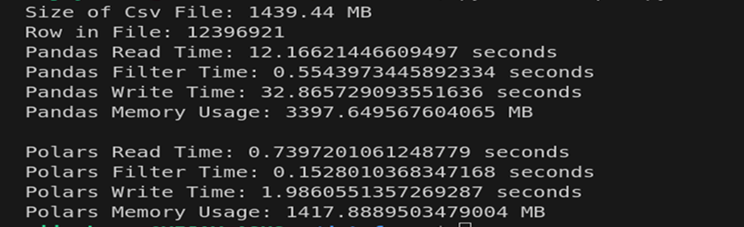
This comparison will help us understand the performance differences and strengths of Polars in relation to Pandas when handling data manipulation tasks.
5. Benchmark Results Comparison
After running the benchmarking scripts, the following metrics were observed for the large_file.csv dataset:

Explanation:
- Reading: Polars' multi-threaded execution allows it to load the file 16.4 times faster than Pandas.
- Filtering: Polars processes filters more efficiently using optimized columnar storage, completing it 3.7 times faster.
- Writing: Polars outshines Pandas significantly in write operations, achieving 16.5 times faster execution.
- Memory Usage: Polars reduces memory consumption by more than half due to its efficient use of columnar data representation and zero-copy reads.
Analysis and Takeaways
The benchmark results demonstrate Polars' dominance in handling large datasets. Key insights include:
- Scalability: Polars' multi-threading architecture and efficient memory management make it better suited for massive data processing.
- Efficiency: By reducing memory overhead and leveraging lazy evaluation, Polars handles operations more seamlessly, even on constrained systems.
- Practical Implication: Polars is especially effective for workloads involving large datasets or where speed and memory optimization are critical.
How Polars Addresses Pandas’ Limitations
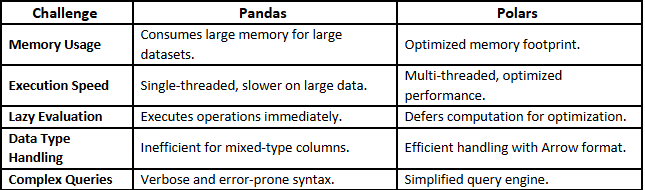
When to Choose Polars
Polars is ideal when:
1. Working with Large Datasets: It handles billions of rows without exhausting memory.
2. Building Data Pipelines: Lazy evaluation and efficient memory management make Polars perfect for production pipelines.
3. Executing Complex Queries: Its expressive API simplifies transformations.
4. Maximizing Hardware: Multi-threading utilizes modern CPUs effectively.
Conclusion
Polars is not just an alternative to Pandas but a next-generation tool for data manipulation. Its speed, scalability, and innovative features make it a standout choice for data professionals handling modern workloads.
While Pandas remains a reliable library for smaller datasets and simpler tasks, Polars offers unparalleled performance for those looking to tackle large-scale data challenges efficiently. Whether you're experimenting locally or deploying in production, Polars is well-equipped to meet your needs.