
The field of LLM agents is expanding rapidly, but measuring their performance remains a challenge. LangSmith's evaluation framework is useful in this situation. Evaluating correctness, cost, latency, tokens used, and quality is crucial whether you're creating a basic calculator or a multi-modal reasoning agent.
In this Blog, we’ll show you how to:
- Leverage LangSmith’s evaluation framework for your agents.
- Create and run a simple LLM agent with a custom tool.
- Measure your agent’s performance with a custom evaluator using LangSmith
Prerequisites
Before we begin, make sure you have :
- A Basic Understanding of LangChain, Agents and Tools.
- An OpenAI API Key.
- A LangSmith account and API key (get one here).
- Basic familiarity with Python (>3.8).
Why we need Evaluation on LLM’s?
Considering LLMs don't always behave predictably, even minor adjustments to prompts, models, or inputs can have a big impact on results. Evaluations provide a quantitative means of measuring the effectiveness of LLM applications. Evaluations offer an organized method for locating issues, comparing modifications made to your application over time, and creating AI applications that are more dependable. This is where LangSmith Evaluation comes to the rescue.
LangSmith Evaluation
In LangSmith Evaluations are made up of 3 components.
- Dataset: A dataset is a collection consisting of test inputs and optional expected outputs.
- Target Function: A target function that defines what you're evaluating. For example, this may be one LLM call that includes the new prompt you are testing, a part of your application or your end-to-end application.
- Evaluators: Evaluators are functions that score how well your application performs on a particular example.
That’s enough of the concepts! Let’s dive into the code.
Install Dependencies:
pip install -U langchain langchain_openai langsmith openevals
Create API key:
- Langsmith API Key: Go to the LangSmith Settings and then Create API Key.
- OpenAI API Key: Navigate to OpenAI API keys page and then Create API Key.
Set up your environment:
export LANGSMITH_TRACING=true export LANGSMITH_API_KEY="<langchain-api-key>" export OPENAI_API_KEY="<openai-api-key>"
Creating a simple Agent with Calculator Tool:
import asyncio
from langchain.agents import tool, initialize_agent, AgentType
from langchain_openai import ChatOpenAI
@tool
def calculator(expression: str) -> float:
""" Evaluates a mathematical expression and returns the result.
Args:
expression (str): A string representing a mathematical expression to be evaluated.
The expression should be a valid Python arithmetic expression.
Returns:
float: The result of evaluating the expression.
"""
return eval(expression)
llm = ChatOpenAI(temperature=0)
agent = initialize_agent( tools=[calculator], llm=llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True )
def run_agent(inputs):
return agent.invoke(inputs["question"])
Create a dataset:
from langsmith import Client
client = Client()
dataset = client.create_dataset(dataset_name="Calculator")
examples =
[
{"inputs": {"question": "4 * 5"}, "outputs": {"answer": "20"}},
{"inputs": {"question": "(3 + 7) * 2"}, "outputs": {"answer": "20"}},
{"inputs": {"question": "12 / 3"}, "outputs": {"answer": "4"}},
]
client.create_examples(dataset_id=dataset.id, examples=examples)
Creating Evaluating Agent code:
from openevals.prompts import CORRECTNESS_PROMPT from simple_agent import run_agent from openevals import create_async_llm_as_judge def correctness_evaluator(inputs: dict, outputs: dict, reference_outputs: dict): evaluator = create_llm_as_judge( prompt=CORRECTNESS_PROMPT, model="openai:o3-mini", feedback_key="correctness", ) eval_result = evaluator( inputs=inputs, outputs=outputs, reference_outputs=reference_outputs ) return eval_result
Run and View Results:
client.evaluate( run_agent, data="Calculator", evaluators=[correctness_evaluator], experiment_prefix="test-eval", max_concurrency=2, )
Click the link returned out by your evaluation run to access the LangSmith Experiments UI and explore the results of the experiment. The results will be as follows.
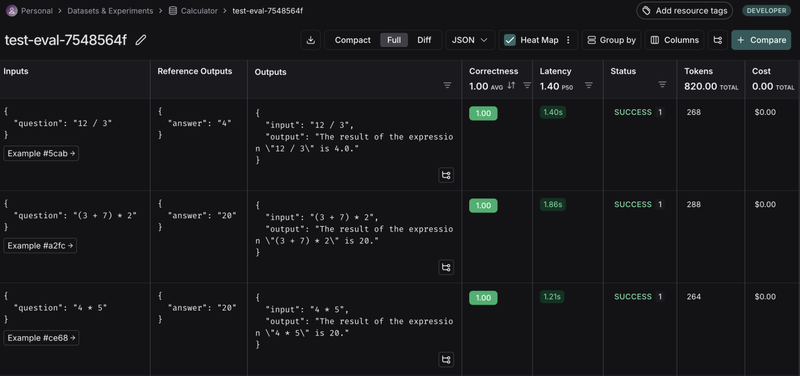
It provides all the details about the latency, correctness, number of tokens used, and the cost employed during the agent execution. In this way we can evaluate the metrics of our simple LLM agent.
Conclusion :
LangSmith takes LLM evaluation from “gut feeling” to metrics that matter. Whether you’re running a simple calculator or a complex LangGraph agent, integrating LangSmith evaluation into your dev loop is a no-brainer.