
Efficiently handling large datasets is essential for many data processing workflows. While Pandas is an excellent tool for loading and manipulating SQL data, it can struggle with large datasets, potentially overwhelming system memory and slowing performance. In this post, we will explore three methods to load SQL data into Pandas:
- Naive Loading (Basic read_sql)
- Batching (Using chunksize)
- Batching with Server-Side Cursors (Streaming)
We’ll discuss how each approach works, their advantages and limitations, and guide you in selecting the most suitable method for your needs. Additionally, we’ll explore how to reduce memory usage and avoid performance bottlenecks when working with large datasets.
1. Naive Approach: Loading Data All at Once
The simplest way to load data into Pandas is by using the read_sql() method. This reads the entire dataset from the SQL database into memory as a DataFrame. While it is quick and easy, this method becomes problematic when dealing with large datasets, as it attempts to load everything into memory at once, which can result in memory overflow or degraded performance.
import pandas as pd
from sqlalchemy import create_engine
def load_data_naive():
engine = create_engine("postgresql://username:password@localhost/db_name")
df = pd.read_sql("SELECT * FROM large_table", engine)
print(f"Loaded {len(df)} rows")
if __name__ == '__main__':
load_data_naive()
Memory Consumption Analysis
To analyze memory usage, you can use Fil, a Python memory profiler that tracks and identifies memory usage over time. Here’s how to install Fil and run it:
pip install filprofiler
Once installed, run your script with:
fil-profile run your_script.py
Why Use Fil?
- Identifies memory bottlenecks: Pinpoints where your script consumes memory.
- Tracks peak memory usage: Monitors memory consumption during execution.
- Detects inefficiencies: Highlights cases where data may be unnecessarily duplicated.
Fil will produce an HTML report showing memory usage by each line of code. Now, let’s use it to measure the memory consumption in three approaches to loading SQL data into Pandas.
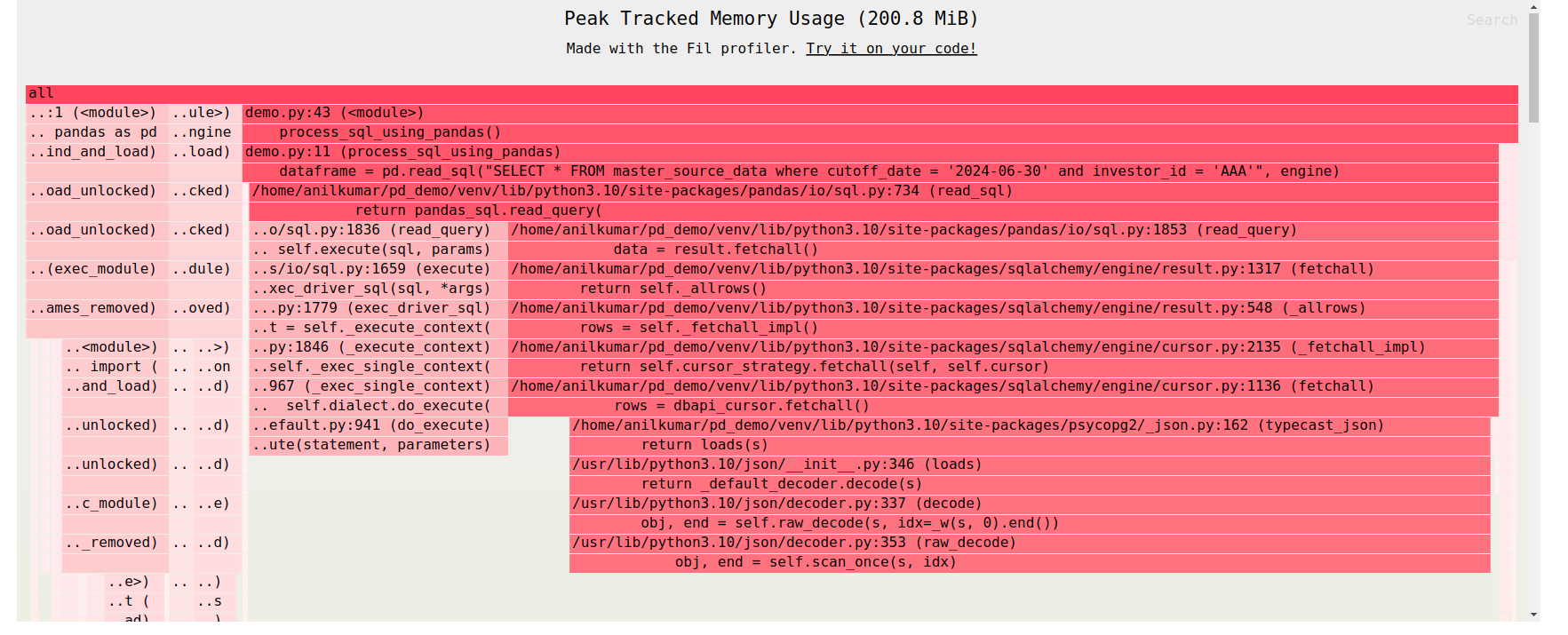
Memory Breakdown
When we profile the memory usage, we see that the same data is being loaded into memory multiple times:
1. Fetching data: The database cursor retrieves all rows using dbapi_cursor.fetchall( ).
2. SQLAlchemy processing: SQLAlchemy processes the data, possibly performing additional formatting or transformations.
3. Converting to tuples: Pandas converts the data into Python tuples.
4. Converting to arrays: Finally, Pandas converts these tuples into arrays for its DataFrame.
This results in the same data existing in multiple forms, consuming far more memory than necessary.
Pros and Cons
Pros
- Simple to implement and use.
- Works well for small datasets.
Cons
- Loads the entire dataset into memory at once, which can lead to memory overflow for large datasets.
- Uses more memory as the data is held in multiple formats temporarily (database cursor, SQLAlchemy, Pandas).
2. Batching with chunksize: Processing Data in Smaller Batches
Pandas provides a chunksize parameter in read_sql(), allowing you to load data in smaller, more manageable chunks. Instead of loading the entire dataset into memory, this approach processes the data in pieces, which significantly reduces memory usage.
import pandas as pd
from sqlalchemy import create_engine
def load_data_with_batching():
engine = create_engine("postgresql://username:password@localhost/db_name")
for chunk in pd.read_sql("SELECT * FROM large_table", engine, chunksize=1000):
print(f"Processing chunk with {len(chunk)} rows")
# Do something with the chunk
if __name__ == '__main__':
load_data_with_batching()
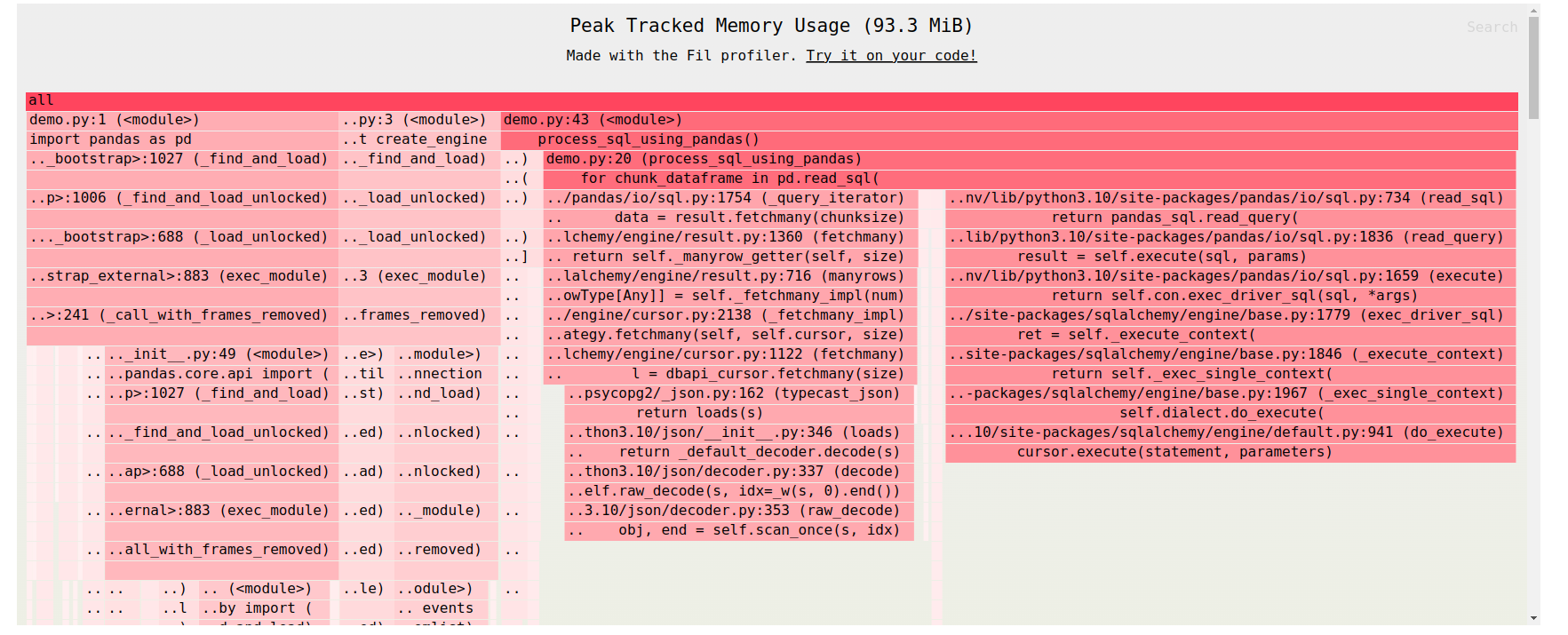
Memory Usage Reduction
By using chunksize, we can significantly reduce memory usage — for example, from 200MB down to around 90MB. However, there's still a catch. SQLAlchemy uses a client-side cursor, which means that even though we’re processing data in smaller chunks, the entire dataset is still pulled into memory first. After that, the data is processed in batches of 1,000 rows at a time for Pandas.
This can still be a problem if you're dealing with really large datasets because that initial fetch of the full data into memory can be overwhelming. It's definitely a step up in efficiency, but it’s not quite the full memory optimization that some larger datasets might require.
Pros and Cons
Pros
- More memory-efficient: Only one chunk of data is in memory at a time.
- Better scalability: Performs better with larger datasets.
Cons
- SQLAlchemy still loads the entire dataset into memory initially, even though it processes it in smaller chunks.
- More complex to implement than the naive approach.
3. Server-Side Cursors: True Streaming of Data
For the most memory-efficient approach, server-side cursors (AKA Streaming) enable true streaming of data. This method allows the database to send data directly to Pandas in batches, without ever loading the entire result set into memory on the client side.
Enabling Server-Side Cursors
To enable server-side cursors in SQLAlchemy, use the execution_options( ) method with stream_results=True:
engine.execute("SELECT * FROM your_table", execution_options={"stream_results": True})
import pandas as pd
from sqlalchemy import create_engine
def load_data_with_server_side_cursor():
engine = create_engine("postgresql://username:password@localhost/db_name")
conn = engine.connect().execution_options(stream_results=True)
for chunk in pd.read_sql("SELECT * FROM large_table", conn, chunksize=1000):
print(f"Processing chunk with {len(chunk)} rows")
# Do something with the chunk
if __name__ == '__main__':
load_data_with_server_side_cursor()
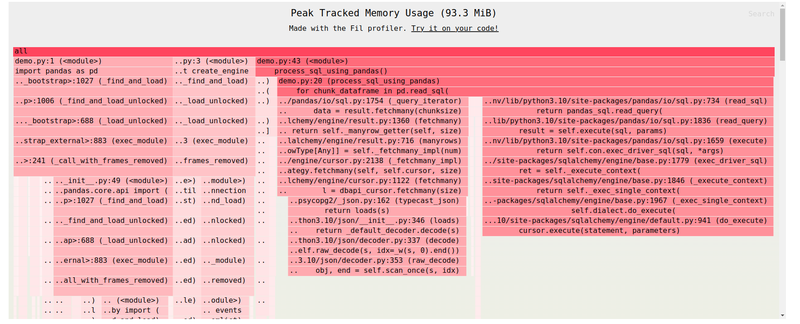
After making this change, the memory used by the database rows and the DataFrame becomes almost nothing. The only memory being used now is from the libraries we’ve imported.
Pros and Cons
Pros
- True streaming: Only a small batch is in memory at a time, ensuring scalability and efficiency.
- Minimal memory usage: Great for handling very large datasets without affecting system memory.
Cons
- More complex setup: Requires changes to the database connection and configuration.
- Potential latency: Data is fetched in real-time from the server, which may introduce delays.
Conclusion
Efficient memory management is crucial when working with large datasets in Pandas. Here’s a quick summary:
- Naive Approach: Simple and works for small datasets but can cause memory issues with larger data.
- Batching with chunksize: Balances memory and performance but still requires the full dataset to be initially loaded.
- Server-Side Cursors: The most scalable method, streaming data directly from the server in small batches.
Choose the approach based on your needs:
- Small datasets: Use the Naive Approach for simplicity.
- Medium datasets: Batching with chunksize works well.
- Large datasets: Server-Side Cursors ensure scalability and minimal memory use.
These strategies help optimize workflows, prevent bottlenecks, and improve efficiency when handling SQL data in Pandas.