
Optimizing Memory in Pandas
Pandas is a powerful tool for data manipulation, but working with large datasets can often lead to memory leaks and excessive resource usage, slowing down workflows. To prevent this, optimizing memory usage is essential. In this post, we'll explore key techniques to handle memory more efficiently in Pandas.
Understanding Data Types (dtypes) in Pandas
In Python, especially with Pandas, data types (dtypes) are essential for managing and optimizing memory usage and performance in data analysis. Here’s a summary of using dtypes effectively, including categorical types, numerical data, and pyarrow for enhanced performance.
Common Data Types in Pandas
1. Integer (int):
- Suitable for columns with whole numbers (e.g., age, counts).
- Options include int8, int16, int32, and int64, which specify the memory each integer takes.
- Use smaller types like int8 or int16 if the range of values is small, as they use less memory.
2. Float (float):
- Used for columns with decimal numbers (e.g., height, weight).
- Options include float32 and float64, with float32 using less memory.
- When precision isn’t crucial, use float32 for memory efficiency.
3. Object (object):
- Stores mixed or textual data (e.g., strings).
- Flexible but memory-intensive, especially with large text data.
- Alternative: Convert text-based categorical data to category dtype for memory savings.
Specialized Data Types for Efficiency
1. Categorical (category):
- Ideal for columns with repeated text values, such as categories or labels (e.g., country, gender).
- Saves memory by storing each unique value once and using integer codes internally.
- Best for columns with a limited number of unique values but a high frequency of repetition, drastically reducing memory usage.
2. Datetime (datetime64):
- Designed for date and time data, enabling efficient time-based indexing and operations.
- Ideal for time series data and date calculations, such as filtering by date range.
Advanced Data Types with pyarrow
The pyarrow library enhances Pandas’ memory efficiency, particularly for large text datasets. By using pyarrow, you can speed up data processing and reduce memory usage.
Using pyarrow with Pandas:
- Enable pyarrow string storage by setting dtype="string[pyarrow]".
- pyarrow can be especially useful when working with large text datasets, as it’s faster and more memory-efficient than the traditional object type.
Advantages of pyarrow:
- Reduces memory usage by storing strings more compactly.
- Provides faster performance due to optimized memory management.
Techniques to Optimize Memory in Pandas
1. Choose the Right dtype:
- Smaller Data Types: Select smaller types, such as int8 or float32, to save memory, balancing precision with memory requirements.
- Convert Repetitive Text: For columns with repeated values, convert to category to achieve significant memory savings.
- Use pyarrow for Text Data: When working with large-scale text, use pyarrow strings to enhance both performance and memory efficiency.
# Create a large dataset with approximately 50,000 rows
data = {
'col1': np.random.choice(['AK6', 'ANQ', 'AAA', 'AK6', 'BNQ'], size=50000),
'col2': np.random.choice(['X', 'Y', 'Z', 'X', 'Z'], size=50000),
'col3': np.random.choice(['apple', 'banana', 'cherry', 'date', 'apple'], size=50000),
'num': np.random.rand(50000),
}
dtypes = {
'col1': 'category',
'col2': 'category',
'col3': 'string [pyarrow]',
'num': 'int8',
}
# Create DataFrame with default string (object) type
df_object = pd.DataFrame(data)
# Create DataFrame with appropriate column types using dtypes
df = pd.DataFrame(data).astype(dtypes)
#checking memory usage
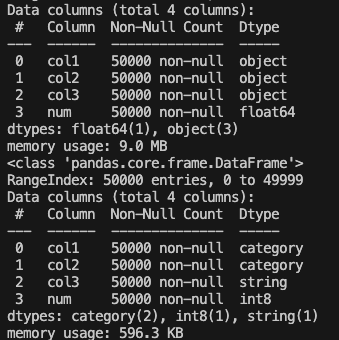
mem_object = df_object.info(memory_usage='deep')
df_mem = df.info(memory_usage='deep')
figure 1.1 : using dtypes to reduce memory usage
2. Select Only Required Columns:
- Minimizing columns to only those needed reduces in-memory storage, potentially improving performance up to 2X.
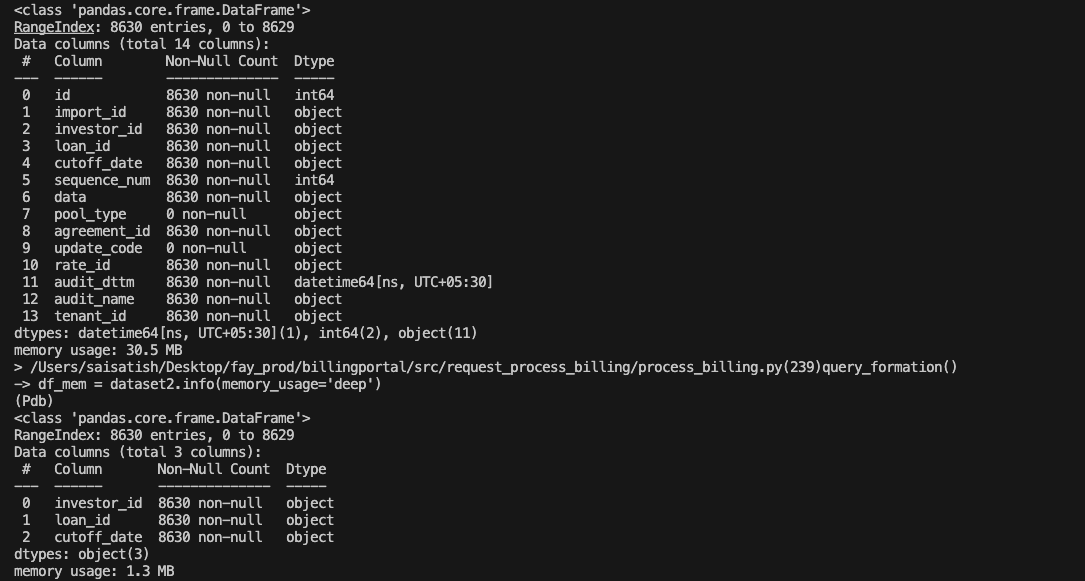
query1 = "SELECT * FROM master_source_data WHERE cutoff_date='07/31/2024' and investor_id='AK6'" query2 = "SELECT investor_id, loan_id, cutoff_date FROM master_source_data WHERE cutoff_date='07/31/2024' and investor_id='AK6'" data1 = conn.execute(query1, clause_params) data_list1 = data1.fetchall() fields1 = data_list1._metadata._keys #pylint: disable = W0212 dataset1 = pd.DataFrame(data, columns=fields1) data2= conn.execute(query2, clause_params) data_list2 = data2.fetchall() fields2 = data_list2._metadata._keys #pylint: disable = W0212 dataset2 = pd.DataFrame(data, columns=fields2) mem_object = dataset1.info(memory_usage='deep') df_mem = dataset2.info(memory_usage='deep')
figure 1.2 : selecting required column
Conclusion
Efficient memory management is key to speeding up Pandas operations, especially when handling large datasets. By following these techniques—correctly defining data types, selecting only required columns, optimizing numeric columns, utilizing pyarrow, and leveraging Pandas category dtypes—you can dramatically reduce memory consumption and make your data workflows more performant. Apply these strategies in your next project to avoid memory bottlenecks and keep your Pandas operations fast and efficient.