
Your database can return perfectly valid responses—and still be wrong.
No crashes. No alerts. No visible failures.
Just incorrect data quietly making its way through your system.
This is what concurrency issues look like in production environments.
Lost updates, dirty reads, inconsistent datasets, these don’t fail loudly. They pass through APIs, get stored, trigger downstream logic, and only surface when something feels “off.”
At that point, the issue is no longer technical. It becomes a question of data integrity, operational reliability, and control.
What’s Actually Happening
Concurrency occurs when multiple processes interact with the same data at the same time.
In any real-world system, financial platforms, enterprise applications, digital infrastructure, this is not an edge case.
It is the default.
- Multiple users updating the same records
- Background jobs running alongside real-time transactions
- Distributed services interacting with shared datasets
Think payments, trading systems, loan processing—multiple users, services, or jobs interacting with the same rows simultaneously.
To make this safe, databases rely on transactions, built around ACID guarantees:
- Atomicity - All operations fully succeed or fail
- Consistency - The database remains valid
- Isolation - Transactions don’t interfere with each other unpredictably
- Durability - Committed data persists
Among these, Isolation is where things get interesting, and where most real-world issues begin.
Where It Breaks: Real Concurrency Problems
These are not theoretical problems. They emerge naturally when your system has parallel activity.
Lost Updates
Two transactions update the same row at the same time:
-- Transaction 1
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- Transaction 2
UPDATE accounts SET balance = balance - 50 WHERE id = 1;
If both read the same initial balance (say ₹1000), they calculate independently and overwrite each other.
Instead of ending at ₹850, you might end up with ₹900.
One transaction silently overrides the other. No error is thrown. The system continues to function. But the data is wrong.
In financial systems, this isn’t a bug—it’s a reconciliation error.
Dirty Reads
One transaction reads data that hasn’t been committed yet.
If the original transaction rolls back, the second transaction has already used invalid data.
This becomes critical when decisions are triggered immediately—fraud checks, credit approvals, eligibility rules.
You’re not just reading bad data, but you’re acting on it.
Phantom Reads
A transaction queries a dataset twice and gets different results because rows were added or removed in between.
This breaks assumptions about consistency especially in:
- Reporting
- Pagination
- Validation logic
These issues aren’t rare edge cases. They show up under load, in real systems, when concurrency is no longer theoretical.
How Databases Try to Maintain Control
Different strategies exist to manage concurrency. Each comes with trade-offs.
1. Lock-Based Control (Pessimistic)
Conflicts are prevented upfront. The idea is simple: don’t let conflicting operations happen at the same time.
- Shared locks allow multiple reads
- Exclusive locks block everything else for writes
This ensures correctness but reduces concurrency.
Under load:
- Requests wait
- Contention increases
- Latency rises
Deadlocks can occur, requiring retries and increasing system unpredictability.
Deadlocks
Two transactions hold locks that the other requires, and neither can proceed.
Modern databases detect this and terminate one transaction, but this introduces operational overhead:
- Retries are required
- Latency increases
- User experience can degrade
Locking provides strong guarantees, but it comes with measurable trade-offs in performance and system responsiveness.
2. Optimistic Concurrency Control
Conflicts are allowed but validated before committing. Instead of preventing conflicts, this approach assumes they’re rare and checks at commit time.
Typically implemented using:
- Version numbers
- Timestamps
If a conflict is detected, the transaction is retried.
This works well for:
- Read-heavy systems
- Distributed systems
- Low-contention environments
But when conflicts increase, retries become expensive and unpredictable.
3. MVCC — What Most Modern Databases Actually Use
Most modern databases (like PostgreSQL) rely on Multi-Version Concurrency Control (MVCC).
Instead of locking aggressively, the database keeps multiple versions of rows:
- Reads access a consistent snapshot
- Writes create new versions
This enables:
- Higher concurrency
- Reads without blocking writes
- Better performance under load
It’s one of the reasons systems scale well without constant lock contention.
But it does not eliminate conflicts, you still need to understand isolation and write conflicts.
Isolation Levels: The Trade-off You Can’t Avoid
Isolation defines how much inconsistency a system tolerates.
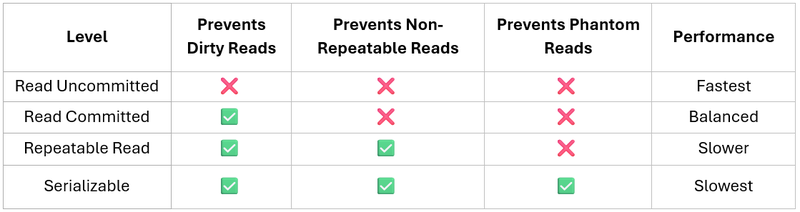
This is always a trade-off:
- Lower isolation → better performance, more risk
- Higher isolation → stronger guarantees, lower concurrency
There’s no universally “correct” choice. It depends on what your system can tolerate.
When to Use What?
This is where most discussions stop, but this is what actually matters.
- High contention systems → pessimistic locking
- Read-heavy or distributed systems → optimistic control / MVCC
- Financial or critical workflows → higher isolation levels
- High-scale systems → versioning + retries + careful design
The right choice isn’t technical—it’s contextual.
What matters is understanding the failure mode you’re willing to accept.
This Is Not Just a Database Concern
Concurrency control is often treated as an internal database detail. But it isn’t just about databases; it’s about correctness under real-world usage.
In reality, it directly affects:
- Data accuracy across systems
- Consistency in reporting
- Reliability of automated decisions
- Operational visibility and control
In distributed and high-scale environments, even small inconsistencies can propagate quickly.
The Real Failure Mode: Silent Data Drift
Systems rarely fail because they crash.
They fail because:
Data slowly diverges from what it should be.
- Numbers don’t reconcile
- Reports differ across systems
- Manual corrections increase
- Confidence in data decreases
By the time it’s detected, the issue is already embedded across workflows.
The Question That Actually Matters
This isn’t just a technical decision.
It’s an operational one.
The real question is not:
“Which isolation level should we use?”
It is:
“If our system is slightly wrong, how long before we notice, and what does it impact?”
Because concurrency issues don’t break systems.
They quietly compromise accuracy, control, and trust in data.
Closing Perspective
As systems scale, whether in financial services, enterprise platforms, or digital infrastructure, the challenge is not just handling more data.
It is maintaining consistency under parallel activity.
Concurrency control sits at the center of that challenge.
Handled well, it enables systems to scale with confidence.
Handled poorly, it introduces risk that remains invisible, until it becomes operationally significant.